
If you like this piece and want to support my independent reporting and analysis, why not subscribe to my premium newsletter?
It’s $70 a year, or $7 a month, and in return you get a weekly newsletter that’s usually anywhere from 5,000 to 18,000 words, including vast, detailed analyses of NVIDIA, Anthropic and OpenAI’s finances, and the AI bubble writ large. I recently put out the timely and important Hater’s Guide To The SaaSpocalypse, another on How AI Isn't Too Big To Fail, and a deep (17,500 word) Hater’s Guide To OpenAI.
Subscribing to premium is both great value and makes it possible to write these large, deeply-researched free pieces every week.
Soundtrack: Muse — Stockholm Syndrome
I think the most enlightening thing about AI is that it shows you how even the most mediocre text inspires some sort of emotion. Soulless LinkedIn slop makes you feel frustration with a person for their lack of authenticity, but you can still imagine how they forced it out of their heads. You still connect with them, even if it’s in a bad way.
AI copy is dead. It is inert. The reason you can spot it is that it sounds hollow. I don’t care if a website says stuff on it because I typed in, just like I don’t care if it responds in a way that sounds human, because it all feels like nothing to me. I am not here to give a website respect, I will not be impressed by a website, nor will I grant a website any extra credit if it can’t do the right thing every time. The computer is meant to work for me. If the computer doesn’t do what I want, I change the kind of computer I use. LLMs will always hallucinate, their outputs are not trustworthy as a result, they cannot be deterministic, and any chance of any mistakes of any kind are unforgivable. I don’t care how the website made you feel: it’s a machine that doesn’t always work, and that’s not a very good machine.
I feel nothing when I see an LLM’s output. Tell me thank you or whatever, I don’t care. You’re a website. Oh you can spit out code? Amazing. Still a website.
Perhaps you’ve found value in LLMs. Congratulations! You should feel no compulsion to have to convince me, nor should you feel any pride in using a particular website. And if you feel you’re being judged for using AI, perhaps you should ask why you feel so vilified? Did the industry do something to somehow warrant judgment? Is there something weird or embarrassing about the product, such as it famously having a propensity to get things wrong? Perhaps it loses billions of dollars? Oh, it’s damaging to the environment too? And people are telling outright lies about it and constantly saying it’ll replace people’s jobs? And the CEOs are all greedy oafish sociopaths? Did you try being cloying, judgmental, condescending, and aggressive to those who don’t like AI? Oh, that didn’t work? I can’t imagine why.
Sounds embarrassing! You must really like that website.
ChatGPT is a website. Claude is a website. While I guess Claude Code runs in a terminal window, that just means it’s an app, which I put in exactly the same mental box as I do a website.
Yet everything you read or hear or see about AI does everything it can to make you think that AI is something other than a website or an app. People that “discover the power of AI” immediately stop discussing it in the same terms as Microsoft Word, Google, or any other app or website. It’s never just about what AI can do today, but always about some theoretical “AGI” or vague shit about “AI agents” that are some sort of indeterminate level of “valuable” without anyone being able to describe why.
Truly useful technology isn’t described in oblique or hyperbolic terms. For example, last week, IBM’s Dave McCann described using a series of “AI agents” to Business Insider
The agent — it's actually a collection of AI agents and assistants — scans McCann's calendar for client meetings and drafts a list of 10 things he needs to know for each one. The goal, McCann told Business Insider, was to free up time he and his staff spent preparing for the meetings.
Sounds like a website to me.
The agent reviews in-house data, what IBM and the client are doing in the market, external data, and account details — such as project status and services sold and purchased, McCann said. It can also identify industry trends and client needs by, for example, reviewing a firm's annual report and identifying a corresponding service IBM could provide.
Sounds like a website using an LLM to summarize stuff to me. Why are we making all this effort to talk about what a website does?
Digital Dave also saves McCann's team time, he said, because the three or four staffers who used to spend hours pulling together insights for the prep calls are now free to do other work.
"It's not just about driving efficiencies, but it's really about transforming how work gets done," McCann said.
My friend, this isn’t a “series of agents.” It’s an LLM that looks at stuff and spits out an answer. Chatbots have done this kind of thing forever. These aren’t “agents.” “Agents” makes it sound like there’s some sort of futuristic autonomous presence rather than a chatbot that’s looking at documents using technology that’s guaranteed to hallucinate incorrect information.
One benefit of building agents, McCann said, is that IBMers who develop them can share them with others on their team or more broadly within the company, "so it immediately creates that multiplier effect."
Many of the people who report to him have created agents, he said. There's a healthy competition, McCann said, to engineer the most robust digital sidekicks, especially because workers can build off of what their colleagues created.
Here’s a fun exercise: replace the word “agent” with “app,” and replace “AI” with “application.” In fact, let’s try that with the next quote:
Apps can handle a range of functions, including gathering information, processing paperwork, drafting communications, taking meeting minutes, and pulling research. It's still early, but these systems are quickly becoming a major focus of corporate application efforts as companies look to turn applications into something that can actually take work off employees' plates.
A variety of functions including searching for stuff, looking at stuff, generating stuff, transcribing a meeting, and searching for stuff. Wow! Who gives a fuck. Every “AI agent” story is either about code generation, summarizing some sort of information source, or generating something based on an information source that you may or may not be able to trust.
“Agent” is an intentional act of deception, and even “modern” agents like OpenClaw and its respective ripoffs ultimately boil down to “I can send you a reminder” or “I can transcribe a text you send me.”
Yet everybody seems to want to believe these things are “valuable” or “useful” without ever explaining why. A page of OpenClaw integrations claiming to share “real projects, real automations [and] real magic” includes such incredible, magical use cases as “reads my X bookmarks and discusses them with me,” “check incoming mail and remove spam,” “researches people before meetings and creates briefing docs,” “schedule reminders,” “tracking who visits a website” (summarizing information), and “using voice notes to tell OpenClaw what to do,” which includes “distilling market research” (searching for stuff) and “tightening a proposal” (generating stuff after looking at it).
I’d have no quarrel with any of this if it wasn’t literally described as magical and innovative. This is exactly the shit that software has always done — automations, shortcuts, reminders, and document work. Boring, potentially useful stuff done in an inefficient way requiring a Mac Mini and hundreds of dollars a day of API calls.
Even Stephen Fry’s effusive review of the iPad from 2010, in referring to it as a “magical object,” still referred to it as “class,” “a different order of experience,” remarking on its speed, responsiveness, its “smooth glide,” and remarking that it’s so simple. Even Fry, a writer beloved for his effervescence and sophisticated lexicon, was still able to point at the things he liked (such as the design and simplicity) in clear terms. Even in couching it in terms of the future, Fry is still able to cogently explain why he’s excited about the present.
Conversely, articles about Large Language Models and their associated products often describe them in one of three ways:
- As if their ability to try to do some of a task allows them to do the entire task.
- As if their ability to do tasks is somehow impressive or a justification for their cost.
- An excuse for why they cannot do more hinged on something happening in the future.
This simply doesn’t happen outside of bubbles. The original CNET review of the iPhone — a technology I’d argue literally changed the way that human beings live their lives — still described it in terms that mirrored the reality we live in:
THE GOOD The Apple iPhone has a stunning display, a sleek design and an innovative multitouch user interface. Its Safari browser makes for a superb web surfing experience, and it offers easy-to-use apps. As an iPod, it shines.
THE BAD The Apple iPhone has variable call quality and lacks some basic features found in many cellphones, including stereo Bluetooth support and a faster data network. Integrated memory is stingy for an iPod, and you have to sync the iPhone to manage music content.
THE BOTTOM LINE Despite some important missing features, a slow data network and call quality that doesn't always deliver, the Apple iPhone sets a new benchmark for an integrated cellphone and MP3 player.
I’d argue that technologies like cloud storage, contactless payments, streaming music, and video and digital photography have transformed our societies in ways that were obvious from the very beginning. Nobody sat around cajoling us to accept that we’d need to sunset our Nokia 3210s and get used to touchscreens because it was blatantly obvious that it was better on using the first iPhone.
Nobody ostracized you for not being sufficiently excited about iPhone apps. Git, launched in 2005, is arguably one of the single-most transformational technologies in tech history, changing how software engineers built all kinds of software. And I’d argue that Github, which came a few years later, was equally transformational.
Editor’s note: If you used SourceForge or Microsoft Visual SourceSafe, which earned the nickname Microsoft Visual SourceShredder due to the catastrophic (and potentially career-ending) ways it failed, you know.
I can’t find a single example of somebody being shamed for not being sufficiently excited, other than people arguing over whether Git was the superior version control software, or saying that Github, a cloud-based repository for code and collaboration, was obvious in its utility. Those that liked it didn’t feel particularly defensive. Even articles about GitHub’s growth spoke entirely in terms rooted in the present.
I realize this was before the hyper-polarized world of post-Musk Twitter, one where venture capital and the tech industry in general was a fraction of the size, but it’s really weird how different it feels when you read about how the stuff that actually mattered was covered.
I must repeat that this was a very different world with very different incentives. Today’s tech industry is a series of giant group chats across various social networks and physical locations, with a much-larger startup community (yCombinator’s last batch had 199 people — the first had 8) influenced heavily by the whims of investors and the various cults of personality in the valley. While social pressure absolutely existed, the speed at which it could manifest and mutate was minute in comparison to the rabid dogs of Twitter or the current state of Hackernews. There were fewer VCs, too.
In any case, no previous real or imagined tech revolution has ever inspired such eager defensiveness, tribalism or outright aggression toward dissenters, nor such ridiculous attempts to obfuscate the truth about a product outside of cryptocurrency, an industry with obvious corruption and financial incentives.
What Makes People So Attached To and Protective Of LLMs?
We’ve never had a cult of personality around a specific technology at this scale. There is something that AI does to people — in the way it both functions and the way that people react to it — that inspires them to act, defensively, weirdly, tribally.
I think it starts with LLMs themselves, and the feeling they create within a user.
We all love prompts. We love to be asked questions about ourselves. We feel important when somebody takes interest in what we’re doing, and even more-so when they remember things about it and seem to be paying attention. LLMs are built to completely focus themselves on us and do so while affirming every single interaction.
Human beings also naturally crave order and structure, which means we’ve created frameworks in our head about what authoritative-sounding or looking information looks like, and the language that engenders trust in it. We trust Wikipedia both because it’s an incredibly well-maintained library of information riddled with citations and because it tonally and structurally resembles an authoritative source. Large Language Models have been explicitly trained to deliver information (through training on much of the internet including Wikipedia) in a structured manner that makes us trust it like we would another source massaged with language we’d expect from a trusted friend or endlessly-patient teacher.
All of this is done with the intention of making you forget that you’re using a website. And that deception is what starts to make people act strangely.
The fact that an LLM can maybe do something is enough to make people try it, along with the constant pressure from social media, peers and the mainstream media.
Some people — such as myself — have used LLMs to do things, seen that making them do said things isn’t going to happen very easily, and walked away because I am not going to use a website that doesn’t do what it says.
As I’ve previously said, technology is a tool to do stuff. Some technology requires you to “get used to it” — iPhones and iPads were both novel (and weird) in their time, as was learning to use the Moonlander ZSK — but in basically every example doesn’t involve you tolerating the inherent failings of the underlying product under the auspices of it “one day being better.” Nowhere else in the world of technology does someone gaslight you into believing that the problems don’t exist or will magically disappear.
It’s not like the iPhone only occasionally allowed you to successfully take a photo, and reliable photography was something that you’d have to wait until the iPhone 3GS to enjoy. While the picture quality improved over time, every generation of iPhone all did the same basic thing successfully, reliably, and consistently.
I also think that the challenge of making an LLM do something useful is addictive and transformative. When people say they’ve “learned to use AI,” often they mean that they’ve worked out ways to fudge their prompts, navigate its failures, mitigate its hallucinations, and connect it to various different APIs and systems of record in such a way that it now, on a prompt, does something, and because they’re the ones that built this messy little process, they feel superior — because the model has repeatedly told them that they were smart for doing it and celebrated with them when they “succeeded.”
The term “AI agent” exists as both a marketing term and a way to ingratiate the user. Saying “yeah I used a chatbot to do some stuff” sounds boring, like you’re talking to an app or a website, but “using an AI agent” makes you sound like a futuristic cyber-warrior, even though you’re doing exactly the same thing.
LLMs are excellent digital busyboxes for those who want to come up with a way to work differently rather than actually doing work. In WIRED’s article about journalists using AI, Alex Heath boasts that he “feels like he’s cheating in a way that feels amazing”:
When technology reporter Alex Heath has a scoop, he sits down at his computer and speaks into a microphone. He’s not talking to a human colleague—Heath went independent on Substack last year—he’s talking to Claude. Using the AI-powered voice-to-text service Wispr Flow, Heath transmits his ideas to an AI agent, then lets it write his first draft.
Heath sat down with me last week to showcase how he’s integrated Anthropic’s Claude Cowork into his journalistic process. The AI tool is connected to his Gmail, Google Calendar, Granola AI transcription service, and Notion notes. He’s also built a detailed skill—a custom set of instructions—to help Claude write in his style, including the “10 commandments” of writing like Alex Heath. The skill includes previous articles he’s written, instructions on how he likes his newsletters to be structured, and notes on his voice and writing style.
Claude Cowork then automates the drafting process that used to take place in Heath’s head. After the agent finishes its first draft, Heath goes back and forth with it for up to 30 minutes, suggesting revisions. It’s quite an involved process, and he still writes some parts of the story himself. But Heath says this workflow saves him hours every week, and he now spends 30 to 40 percent less time writing.
The linguistics of “transmitting an idea to an AI agent” misrepresent what is a deeply boring and soulless experience. Alex speaks into a microphone, his words are transcribed, then an LLM burps out a draft. A bunch of different services connect to Claude Cowork and a text document (that’s what the “custom set of instructions” is) that says how to write like him, and then it writes like him, and then he talks to it and then sometimes writes bits of the story himself.
This is also most decidedly not automation. Heath still must sit and prompt a model again and again. He must still maintain connections to various services and make sure the associated documents in Notion are correct. He must make sure that Granola actually gets the transcriptions from his interview. He must (I would hope) still check both the AI transcription and the output from the model to make sure quotes are accurate. He must make sure his calendar reflects accurate information. He must make sure that Claude still follows his “voice and writing style” — if you can call it that given the amount of distance between him and the product.
Per Heath:
“I never did this because I liked being a writer. I like reporting, learning new things, having an edge, and telling people things that will make them feel smart six months from now.”
Well, Alex, you’re not telling anybody anything, your ideas and words come out of a Large Language Model that has convinced you that you’re writing them.
In any case, Heath’s process is a great example of what makes people think they’re “using powerful AI.” Large Language Models are extremely adept at convincing human beings to do most of the work and then credit “AI” with the outcomes. Alex’s process sounds convoluted and, if I’m honest, a lot more work than the old way of doing things. It’s like writing a blog using a machine from Pee-wee’s Playhouse.
I couldn’t eat breakfast that way every morning. I bet it would get old pretty quick.
This is the reality of the Large Language Model era. LLMs are not “artificial intelligence” at all. They do not think, they do not have knowledge, they are conjuring up their own training data (or reflecting post-training instructions from those developing them or documents instructing them to act a certain way), and any time you try and make them do something more-complicated, they begin to fall apart, and/or become exponentially more-expensive.
You’ll notice that most AI boosters have some sort of bizarre, overly-complicated way of explaining how they use AI. They spin up “multiple agents” (chatbots) that each have their own “skills document” (a text document) and connect “harnesses” (python scripts, text files that tell it what to do, a search engine, an API) that “let it run agentic workflows” (query various tools to get an outcome.”
The so-called “agentic AI” that is supposedly powerful and autonomous is actually incredibly demanding of its human users — you must set it up in so many different ways and connect it to so many different services and check that every “agent” (different chatbot) is instructed in exactly the right way, and that none of these agents cause any problems (they will) with each other. Oh, don’t forget to set certain ones to “high-thinking” for certain tasks and make sure that other tasks that are “easier” are given to cheaper models, and make sure that those models are prompted as necessary so they don’t burn tokens.
But the process of setting up all those agents is so satisfying, and when they actually succeed in doing something — even if it took fucking forever and costs a bunch and is incredibly inefficient — you feel like a god! And because you can “spin up multiple agents,” each one ready and waiting for you to give them commands (and ready to affirm each and every one of them), you feel powerful, like you’re commanding an army that also requires you to monitor whatever it does.
Sidebar: the psychological reward of building convoluted systems (which you can call “complex” if you want to feel fancy) is enough to drive somebody mad. OpenAI co-founder Andrej Karpathy recently described “building personal knowledge bases for various topics of research interest,” describing a dramatic and contrived process through which he has, by the sounds of it, created some sort of half-assed Wikipedia clone he can ask questions of using an LLM, with the results (and the content) also generated by AI. A user responded saying that he’d been doing a “less pro version of this using OpenClaw and Obsidian.”
It’s a very Silicon Valley way of looking at the world — a private Wikipedia that you use to…search…things you already know? Or want to know? You could just read a book I guess. Then again, in another recent tweet, Karpathy described drafting a blog post, using an LLM to “meticulously improve the argument over four hours,” then watch as the LLM “demolished the entire argument and convinced him the opposite was in fact true,” suggesting he didn’t really do much thinking about it in the first place.
God, these people sound like lunatics! I’m sorry! What’re you talking about man? You argued with a website for hours until it convinced you of something then it manipulated you into believing you were wrong? Why do you respect it? It’s a website! It doesn’t have opinions or thoughts or feelings. You are arguing with a calculator trained to sound human.
The reason that LLMs have become so interesting for software engineers is that this is already how they lived. Writing software is often a case of taping together different systems and creating little scripts and automations that make them all work, and the satisfaction of building functional software is incredible, even at the early stages.
Large Language Models perform an impression of automating that process, but for the most part force you, the user, to do the shit that matters, even if that means “be responsible for the code that it puts out.” Heath’s process does not appear to take less time than his previous one — he’s just moved stuff around a bit and found a website to tell him he’s smart for doing so.
They are Language Models interpreting language without any knowledge or thoughts or feelings or ability to learn, and each time they read something they interpret meaning based on their training data, which means they can (and will!) make mistakes, and when they’re, say, talking to another chatbot to tell it what to do next, that little mistake might build a fundamental flaw in the software, or just break the process entirely.
And Large Language Models — using the media — exist to try and convince you that these mistakes are acceptable. When Anthropic launched its Claude For Finance tool, which claims to “automate financial modeling” with “pre-built agents” (chatbots) but really appears to just be able to create questionably-useful models via Excel spreadsheets and “financial research” based on connecting to documents in your various systems, I imagine with a specific system prompt. Anthropic also proudly announced that it had scored a 55.3% on the Finance Agent Test.
I hate to repeat myself, but I will not respect a website, and I will not tolerate something being “55% good” at something if its alleged use case is that it’s an artificial intelligence.
Yet that’s the other remarkable thing about the LLM era — that there are people who are extremely tolerant of potential failures because they believe they’re either A) smart enough to catch them or B) smart enough to build systems that do so for them, with a little sprinkle of “humans make mistakes too,” conflating “an LLM that doesn’t know anything fucking up by definition” with “a human being with experiences and the capacity for adaptation making a mistake.”
Sidenote: I also believe that there is a contingent of people who are very impressed with LLMs who are really just impressed with the coding language Python. Python is awesome! It can organize your files, scrape websites, extra text from PDFs, manage your inbox, and send emails. Anyone you read talking about how LLMs “allowed them to look through a massive dataset” is likely using Python. Many of the associated tools that LLMs use use Python. Manus, the so-called “intelligent agent” firm that Meta bought last year, daisy-chains Python and Java in an incredibly-inefficient way to sometimes get things right, almost.
I truly have no beef with people using LLMs to speed up Python scripts to do fun little automations or to dig through big datasets, but please don’t try and convince me they’re being futuristic by doing so. If you want to learn Python, I recommend reading Al Sweigart’s Automate The Boring Stuff.
Anytime somebody sneers at you and says you are being “left behind” because you’re not using AI should be forced to show you what it is they’ve created or done, and the specific system they used to do so. They should have to show you how much work it took to prepare the system, and why it’s superior to just doing it themselves.
Karpathy also had a recent (and very long) tweet about “the growing gap in understanding of AI capability,” involving more word salad than a fucking SweetGreen:
So that brings me to the second group of people, who *both* 1) pay for and use the state of the art frontier agentic models (OpenAI Codex / Claude Code) and 2) do so professionally in technical domains like programming, math and research. This group of people is subject to the highest amount of "AI Psychosis" because the recent improvements in these domains as of this year have been nothing short of staggering. When you hand a computer terminal to one of these models, you can now watch them melt programming problems that you'd normally expect to take days/weeks of work. It's this second group of people that assigns a much greater gravity to the capabilities, their slope, and various cyber-related repercussions.
Wondering what those “staggering improvements” are?
TLDR the people in these two groups are speaking past each other. It really is simultaneously the case that OpenAI's free and I think slightly orphaned (?) "Advanced Voice Mode" will fumble the dumbest questions in your Instagram's reels and *at the same time*, OpenAI's highest-tier and paid Codex model will go off for 1 hour to coherently restructure an entire code base, or find and exploit vulnerabilities in computer systems. This part really works and has made dramatic strides because 2 properties: 1) these domains offer explicit reward functions that are verifiable meaning they are easily amenable to reinforcement learning training (e.g. unit tests passed yes or no, in contrast to writing, which is much harder to explicitly judge), but also 2) they are a lot more valuable in b2b settings, meaning that the biggest fraction of the team is focused on improving them. So here we are.
The one tangible (and theoretical!) example Karpathy gives is an example of how hard people work to overstate the capabilities of LLMs. “Coherently restructuring” a codebase might happen when you feed it to an LLM (while also costing a shit-ton of tokens, but putting that aside), or it might not understand at all because Claude Opus is acting funny that day, or it might sort-of fix it but mess something subtle up that breaks things in the future. This is an LLM doing exactly what an LLM does — it looks at a block of text, sees whether it matches up with what a user said, sees how that matches with its training data, and then either tells you things to do or generates new code, much like it would do if you had a paragraph of text you needed to fact-check. Perhaps it would get some of the facts right if connected to the right system. Perhaps it might make a subtle error. Perhaps it might get everything wrong.
This is the core problem with the “checkmate, boosters — AI can write code!” problem. AI can write code. We knew that already. It gets “better” as measured by benchmarks that don’t really compare to real world success, and even with the supposedly meteoric improvements over the last few months, nobody can actually explain what the result of it being better is, nor does it appear to extend to any domain outside of coding.
You’ll also notice that Karpathy’s language is as ingratiating to true believers as it is vague. Other domains are left unexplained other than references to “research” and “math.” I’m in a research-heavy business, and I have tried the most-powerful LLMs and highest-priced RAG/post-RAG research tools, and every time find them bereft of any unique analysis or suggestions.
I don’t dispute that LLMs are useful for generating code, nor do I question whether or not they’re being used by software developers at scale. I just think that they would be used dramatically less if there weren’t an industrial-scale publicity campaign run through the media and the majority of corporate America both incentivizing and forcing them to do so.
Similarly, I’m not sure anybody would’ve been anywhere near as excited if OpenAI and Anthropic hadn’t intentionally sold them a product that was impossible to support long-term.
This entire industry has been sold on a lie, and as capacity becomes an issue, even true believers are turning on the AI labs.
The Great Enshittification of Generative AI
Anthropic’s Products Are Deteriorating In Real Time, And Its Customers Are Victims of A Con
About a year ago, I warned you that Anthropic and OpenAI had begun the Subprime AI Crisis, where both companies created “priority processing tiers” for enterprise customers (read: AI startups like Replit and Cursor), dramatically increasing the cost of running their services to the point that both had to dramatically change their features as a result. A few weeks later, I wrote another piece about how Anthropic was allowing its subscribers to burn thousands of dollars’ worth of tokens on its $100 and $200-a-month subscriptions, and asked the following question at the end:
…do you think that the current version of Claude Code is going to be what you get? Anthropic has proven it’ll rate limit their business customers, what's stopping it from doing the same to you and charging more, just like Cursor?
I was right to ask, as a few weeks ago (as I wrote in the Subprime AI Crisis Is Here) that Anthropic had added “peak hours” to its rate limits, and users found across the board that they were burning through their limits in some cases in only a few prompts. Anthropic’s response was, after saying it was looking into why rate limits were being hit so fast, to say that users were ineffectively utilizing the 1-million-token context window and failing to adjust Claude’s “thinking effort level” based on whatever task it is they were doing.
Anthropic’s customers were (and remain) furious, as you can see in the replies of its thread on the r/Anthropic Subreddit.
To make matters worse, it appears that — deliberately or otherwise — Anthropic has been degrading the performance of both Claude Opus 4.6 and Claude Code itself, with developers, including AMD Senior AI Director Stella Laurenzo, documenting the problem at length (per VentureBeat):
One of the most detailed public complaints originated as a GitHub issue filed by Stella Laurenzo on April 2, 2026, whose LinkedIn profile identifies her as Senior Director in AMD’s AI group.
In that post, Laurenzo wrote that Claude Code had regressed to the point that it could not be trusted for complex engineering work, then backed that claim with a sprawling analysis of 6,852 Claude Code session files, 17,871 thinking blocks and 234,760 tool calls.
The complaint argued that, starting in February, Claude’s estimated reasoning depth fell sharply while signs of poorer performance rose alongside it, including more premature stopping, more “simplest fix” behavior, more reasoning loops, and a measurable shift from research-first behavior to edit-first behavior.
Think that Anthropic cares? Think again:
Anthropic’s public response focused on separating perceived changes from actual model degradation. In a pinned follow-up on the same GitHub issue posted a week ago, Claude Code lead Boris Cherny thanked Laurenzo for the care and depth of the analysis but disputed its main conclusion.
Cherny said the “redact-thinking-2026-02-12” header cited in the complaint is a UI-only change that hides thinking from the interface and reduces latency, but “does not impact thinking itself,” “thinking budgets,” or how extended reasoning works under the hood.
He also said two other product changes likely affected what users were seeing: Opus 4.6’s move to adaptive thinking by default on Feb. 9, and a March 3 shift to medium effort, or effort level 85, as the default for Opus 4.6, which he said Anthropic viewed as the best balance across intelligence, latency and cost for most users.
Cherny added that users who want more extended reasoning can manually switch effort higher by typing /effort high in Claude Code terminal sessions.
Another developer found that Claude Opus 4.6 was “thinking 67% less than it used to,” though Anthropic didn’t even bother to respond. In fact, Anthropic has done very little to explain what’s actually happening, other than to say that it doesn’t degrade its models to better serve demand.
To be clear, this is far from the only time that I’ve seen people complain about these models “getting dumber” — users on basically every AI Subreddit will say, at some point, that models randomly can’t do things they used to be able to, with nobody really having an answer other than “yeah dude, same.”
Back in September 2025, developer Theo Browne complained that Claude had got dumber, but Anthropic near-immediately responded to say that the degraded responses were a result of bugs that “intermittently degraded responses from Claude,” adding the following:
To state it plainly: We never reduce model quality due to demand, time of day, or server load. The problems our users reported were due to infrastructure bugs alone.
Which begs the question: is Anthropic accidentally making its models worse? Because it’s obvious it’s happening, it’s obvious they know something is happening, and its response, at least so far, has been to say that either users need to tweak their settings or nothing is wrong at all. Yet these complaints have happened for years, and have reached a crescendo with the latest ones that involve, in some cases, Claude Code burning way more tokens for absolutely no reason, hitting rate limits earlier than expected or wasting actual dollars spent on API calls.
Some suggest that the problems are a result of capacity issues over at Anthropic, which have led to a stunning (at least for software used by millions of people) amounts of downtime, per the Wall Street Journal:
The reliability of core services on the internet is often measured in nines. Four nines means 99.99% of uptime—a typical percentage that a software company commits to customers. As of April 8, Anthropic’s Claude API had a 98.95% uptime rate in the last 90 days.
This naturally led to boosters (and, for that matter, the Wall Street Journal) immediately saying that this was a sign of the “insatiable demand for AI compute”:
Spot-market prices to access Nvidia’s GPUs, or graphics processing units, in data-center clouds have risen sharply in recent months across the company’s entire product line, according to Ornn, a New York-based data provider that publishes market data and structures financial products around GPU pricing.
Renting one of Nvidia’s most-advanced Blackwell generation of chips for one hour costs $4.08, up 48% from the $2.75 it cost two months ago, according to the Ornn Compute Price Index.
“There’s a massive capacity crunch that’s unlike anything I’ve seen in the more than five years I’ve been running this business,” said J.J. Kardwell, chief executive of Vultr, a cloud infrastructure company. “The question is, why don’t we just deploy more gear? The lead times are too long. Data center build times are long, the power that’s available through 2026 is already all spoken for.”
Before I go any further: if anyone has been taking $2.75-per-hour-per-GPU for any kind of Blackwell GPU, they are losing money. Shit, I think they are at $4.08. While these are examples from on-demand pricing (versus paid-up years-long contracts like Anthropic buys), if they’re indicative of wider pricing on Blackwell, this is an economic catastrophe.
In any case, Anthropic’s compute constraints are a convenient excuse to start fucking over its customers at scale. Rate limits that were initially believed to be a “bug” are now the standard operating limits of using Anthropic’s services, and its models are absolutely, fundamentally worse than they were even a month ago.
A Scenario Illustrating How Anthropic Fucks Over Its Customers
It’s January 14 2026, and you just read The Atlantic’s breathless hype-slop about Claude Code, believing that it was “bigger than the ChatGPT moment,” that it was an “inflection point for AI progress,” and that it could build whatever software you imagined. While you’re not exactly sure what it is you’re meant to be excited about, your boss has been going on and on about how “those who don’t use AI will be left behind,” and your boss allows you to pay $200 for a year’s access to Claude Pro.
You, as a customer, no longer have access to the product you purchased. Your rate limits are entirely different, service uptime is measurably worse, and model performance has, for some reason, taken a massive dip. You hit your rate limits in minutes rather than hours. Prompts that previously allowed you a healthy back-and-forth over a project are now either impractical or impossible.
Your boss now has you vibe-coding barely-functional apps as a means of “integrating you with the development stack,” but every time you feed it a screenshot of what’s going wrong with the app you seem to hit your rate limits again. You ask your boss if he’ll upgrade you to the $100-a-month subscription, and he says that “you’ve got to make do, times are tough.” You sit at your desk trying to work out what the fuck to do for the next four hours, as you do not know how to code and what little you’ve been able to do is now impossible.
This is the reality for a lot of AI subscribers, though in many cases they’ll simply subscribe to OpenAI Codex or another service that hasn’t brought the hammer down on their rate limits.
…for now, at least.
AI Labs’ Capacity Issues Are Financial Poison, As Compute “Demand” Is Impossible To Gauge And Must Be Planned Years In Advance
The con of the Large Language Model era is that any subscription you pay for is massively subsidized, and that any product you use can and will see its service degraded as these companies desperately try to either ease their capacity issues or lower their burn rate.
Yet it’s unclear whether “more capacity” means that things will be cheaper, or better, or just a way of Anthropic scaling an increasingly-shittier experience.
To explain, when an AI lab like Anthropic or OpenAI “hits capacity limits,” it doesn’t mean that they start turning away business or stop accepting subscribers, but that current (and new) subscribers will face randomized downtime and model issues, along with increasingly-punishing rate limits.
Neither company is facing a financial shortfall as a result of being unable to provide their services (rather, they’re facing financial shortfalls because they’re providing their services to customers. And yet, the only people that are the only people paying that price because of these “capacity limits” are the customers.
This is because AI labs must, when planning capacity, make arbitrary guesses about how large the company will get, and in the event that they acquire too much capacity, they’ll find themselves in financial dire straits, as Anthropic CEO Dario Amodei told Dwarkesh Patel back in February:
So when we go to buying data centers, again, the curve I’m looking at is: we’ve had a 10x a year increase every year. At the beginning of this year, we’re looking at $10 billion in annualized revenue. We have to decide how much compute to buy. It takes a year or two to actually build out the data centers, to reserve the data center.
Basically I’m saying, “In 2027, how much compute do I get?” I could assume that the revenue will continue growing 10x a year, so it’ll be $100 billion at the end of 2026 and $1 trillion at the end of 2027. Actually it would be $5 trillion dollars of compute because it would be $1 trillion a year for five years. I could buy $1 trillion of compute that starts at the end of 2027. If my revenue is not $1 trillion dollars, if it’s even $800 billion, there’s no force on earth, there’s no hedge on earth that could stop me from going bankrupt if I buy that much compute.
What happens if you don’t buy enough compute? Well, you find yourself having to buy it last-minute, which costs more money, which further erodes your margins, per The Information:
In another sign of its financial pressures, OpenAI told investors that its gross profit margins last year were lower than projected due to the company having to buy more expensive compute at the last minute in response to higher than expected demand for its chatbots and models, according to a person with knowledge of the presentation. (Anthropic has experienced similar problems.)
In other words, compute capacity is a knife-catching game. Ordering compute in advance lets you lock in a better rate, but having to buy compute at the last-minute spikes those prices, eating any potential margin that might have been saved as a result of serving that extra demand.
Order too little compute and you’ll find yourself unable to run stable and reliable services, spiking your costs as you rush to find more capacity. Order too much capacity and you’ll have too little revenue to pay for it.
It’s important to note that the “demand” in question here isn’t revenue waiting in the wings, but customers that are already paying you that want to do more with the product they paid for. More capacity allows you to potentially onboard new customers, but they too face the same problems as your capacity fills.
This also begs the question: how much capacity is “enough”? It’s clear that current capacity issues are a result of the inference (the creation of outputs) demands of Anthropic’s users. What does adding more capacity do, other than potentially bringing that under control?
OpenAI And Anthropic’s Are Conning Their Customers, Offering Products That Will Reduce In Functionality In A Matter Of Months
This also suggests that Anthropic’s (and OpenAI’s by extension) business model is fundamentally flawed. At its current infrastructure scale, Anthropic cannot satisfactorily serve its current paying customer base, and even with this questionably-stable farce of a product, Anthropic still expects to burn $14 billion. While adding more capacity might potentially allow new customers to subscribe, said new customers would also add more strain on capacity, which would likely mean that nobody’s service improves but Anthropic still makes money.
It ultimately comes down to the definition of the word “demand.”
Let me explain.
Data center development is very slow. Only 5GW of capacity is under construction worldwide (and “construction” can mean anything from a single steel beam to a near-complete building). As a result, both Anthropic and OpenAI are planning and paying for capacity years in advance based on “demand.”
“Demand” in this case doesn’t just mean “people who want to pay for services,” but “the amount of compute that the people who pay us now and may pay us in the future will need for whatever it is they do.”
The amount of compute that a user may use varies wildly based on the model they choose and the task in question — a source at Microsoft once told me in the middle of last year that a single user could take up as many as 12 GPUs with a coding task using OpenAI’s o4-mini — which means that in a very real sense these guys are guessing and hoping for the best.
It also means that their natural choice will be to fuck over their current users to ease their capacity issues, especially when those users are paying on a monthly or — ideally — annual basis. OpenAI and Anthropic need to show continued revenue growth, which means that they must have capacity available for new customers, which means that old customers will always be the first to be punished.
We’re already seeing this with OpenAI’s new $100-a-month subscription, a kind of middle ground between its $20 and $200-a-month ChatGPT subscriptions that appears to have immediately reduced rate limits for $20-a-month subscribers.
To obfuscate the changes further, OpenAI also launched a bonus rate limit period through May 31 2026, telling users that they will have “10x or 20x higher rate limits than plus” on its pricing page while also featuring a tiny little note that’s very easy for somebody to miss:
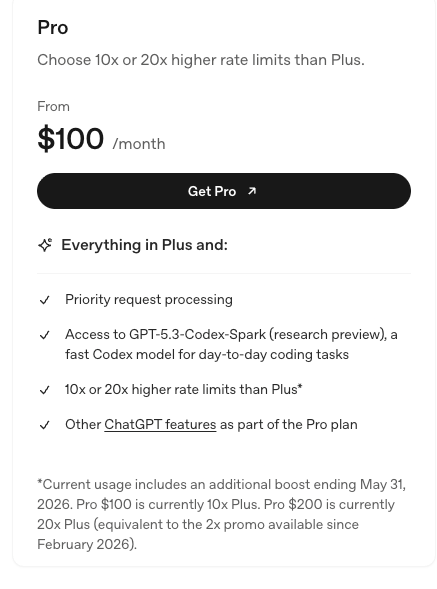
This is a fundamentally insane and deceptive way to run a business, and I believe things will only get worse as capacity issues continue. Not only must Anthropic and OpenAI find a way to make their unsustainable and unprofitable services burn less money, but they must also constantly dance with metering out whatever capacity they have to their customers, because the more extra capacity they buy, the more money they lose.
OpenAI And Anthropic Are Unethical Businesses That Abuse Their Customers
However you feel about what LLMs can do, it’s impossible to ignore the incredible abuse and deception happening to just about every customer of an AI service.
As I’ve said for years, AI companies are inherently unsustainable due to the unreliable and inconsistent outputs of Large Language Models and the incredible costs of providing the services. It’s also clear, at this point, that Anthropic and OpenAI have both offered subscriptions that were impossible to provide at scale at the price and availability that they were leading up to 2026, and that they did so with the intention of growing their revenue to acquire more customers, equity investment and attention.
As a result, customers of AI services have built workflows and habits based on an act of deceit. While some will say “this is just what tech companies do, they get you in when it’s cheap then jack up the price,” doing so is an act of cowardice and allegiance with the rich and powerful.
To be clear, Anthropic and OpenAI need to do this. They’ve always needed to do this. In fact, the ethical thing to do would’ve been to charge for and restrict the services in line with their actual costs so that users could have reliable and consistent access to the services in question. As of now, anyone that purchases any kind of AI subscription is subject to the whims of both the AI labs and their ability to successfully manage their capacity, which may or may not involve making the product that a user pays for worse.
The “demand” for AI as it stands is an act of fiction, as much of that demand was conjured up using products that were either cheaper or more-available. Every one of those effusive, breathless hype-screeds about Claude Code from January or February 2026 are discussing a product that no longer exists. On June 1 2026, any article or post about Codex’s efficacy must be rewritten, as rate limits will be halved.
While for legal reasons I’ll stop short of the most obvious word, Anthropic and OpenAI are running — intentionally or otherwise — deeply deceitful businesses where their customers cannot realistically judge the quality or availability of the service long-term. These companies also are clearly aware that their services are deeply unpopular and capacity-constrained, yet aggressively court and market toward new customers, guaranteeing further service degradations and potential issues with models.
This applies even to API customers, who face exactly the same downtime and model quality issues, all with the indignity of paying on a per-million token basis, even when Claude Opus 4.6 decides to crap itself while refactoring something, running token-intensive “agents” to fix simple bugs or fails to abide by a user’s guidelines.
This is not a dignified way to use software, nor is it an ethical way to sell it.
How can you plan around this technology? Every month some new bullshit pops up. While incremental model gains may seem like a boon, how do you actually say “ok, let’s plan ahead” for a technology that CHANGES, for better or for worse, at random intervals? You’re constantly reevaluating model choices and harnesses and prompts and all kinds of other bullshit that also breaks in random ways because “that’s how large language models work.” Is that fun? Is that exciting? Do you like this? It seems exhausting to me, and nobody seems to be able to explain what’s good about it.
How, exactly, does this change?
Right now, I’d guess that OpenAI has access to around 2GW of capacity (as of the end of 2025), and Anthropic around 1GW based on discussions with sources. OpenAI is already building out around 10GW of capacity with Oracle, as well as locking in deals with CoreWeave ($22.4 billion), Amazon Web Services ($138 billion), Microsoft Azure ($250 billion), and Cerebras (“750MW”).
Meanwhile, Anthropic is now bringing on “multiple gigawatts of Google’s next-generation TPU capacity” on top of deals with Microsoft, Hut8, CoreWeave and Amazon Web Services.
Both of these companies are making extremely large bets that their growth will continue at an astonishing, near-impossible rate. If OpenAI has reached “$2 billion a month” (which I doubt it can pay for) with around 2GW of capacity, this means that it has pre-ordered compute assuming it will make $10 billion or $20 billion a month in a few short years, which fits with The Information’s reporting that OpenAI projects it will make $113 billion in revenue in 2028.
And if it doesn’t make that much revenue — and also doesn’t get funding or debt to support it — OpenAI will run out of money, much as Anthropic will if that capacity gets built and it doesn’t make tens of billions of dollars a month to pay for it.
I see no scenario where costs come down, or where rate limits are eased. In fact, I think that as capacity limits get hit, both Anthropic and OpenAI will degrade the experience for the user (either through model degradation or rate limit decay) as much as they can.
I imagine that at some point enterprise customers will be able to pay for an even higher priority tier, and that Anthropic’s “Teams” subscription (which allows you to use the same subsidized subscriptions as everyone else) will be killed off, forcing anyone in an organization paying for Claude Code (and eventually Codex) via the API, as has already happened for Anthropic’s enterprise users.
Anyone integrating generative AI is part of a very large and randomized beta test. The product you pay for today will be materially different in its quality and availability in mere months. I told you this would happen in September 2024. I have been trying to warn you this would happen, and I will repeat myself: these companies are losing so much more money than you can think of, and they are going to twist the knife in and take as many liberties with their users and the media as they can on the way down.
It is fundamentally insane that we are treating these companies as real businesses, either in their economics or in the consistency of the product they offer.
These are unethical products sold in deceptive ways, both in their functionality and availability, and to defend them is to help assist in a society-wide con with very few winners.
And even if you like this, mark my words — your current way of life is unsustainable, and these companies have already made it clear they will make the service worse, without warning, if they even acknowledge that they’ve done so directly. The thing you pay for is not sustainable at its current price and they have no way to fix that problem.
Do you not see you are being had? Do you not see that you are being used?
Do any of you think this is good? Does any of this actually feel like progress?
I think it’s miserable, joyless and corrosive to the human soul, at least in the way that so many people talk about AI. It isn’t even intelligent. It’s just more software that is built to make you defend it, to support it, to do the work it can’t so you can present the work as your own but also give it all the credit.
And to be clear, these companies absolutely fucking loathe you. They’ll make your service worse at a moment’s notice and then tell you nothing is wrong.
Anyone using a subscription to OpenAI or Anthropic’s services needs to wake up and realize that their way of life is going away — that rate limits will make current workflows impossible, that prices will increase, and that the product they’re selling even today is not one that makes any economic sense.
Every single LLM product is being sold under false pretenses about what’s actually sustainable and possible long term.
With AI, you’re not just the product, you’re a beta tester that pays for the privilege.
And you’re a mark for untrustworthy con men selling software using deceptive and dangerous rhetoric.
The AI Industry Is Surprised That People Are Angry, And It Shouldn’t Be.
I will be abundantly clear for legal reasons that it is illegal to throw a Molotov cocktail at anyone, as it is morally objectionable to do so. I explicitly and fundamentally object to the recent acts of violence against Sam Altman.
It is also morally repugnant for Sam Altman to somehow suggest that the careful, thoughtful, determined, and eagerly fair work of Ronan Farrow and Andrew Marantz is in any way responsible for these acts of violence. Doing so is a deliberate attempt to chill the air around criticism of AI and its associated companies. Altman has since walked back the comments, claiming he “wishes he hadn’t used” a non-specific amount of the following words:
A lot of the criticism of our industry comes from sincere concern about the incredibly high stakes of this technology. This is quite valid, and we welcome good-faith criticism and debate. I empathize with anti-technology sentiments and clearly technology isn’t always good for everyone. But overall, I believe technological progress can make the future unbelievably good, for your family and mine.
While we have that debate, we should de-escalate the rhetoric and tactics and try to have fewer explosions in fewer homes, figuratively and literally.
These words remain on his blog, which suggests that Altman doesn’t regret them enough to remove them.
I do, however, agree with Mr. Altman that the rhetoric around AI does need to change.
Both he and Mr. Amodei need to immediately stop overstating the capabilities of Large Language Models. Mr. Altman and Mr. Amodei should not discuss being “scared” of their models, or being “uncomfortable” that men such as they are in control unless they wish to shut down their services, or that they “don’t know if models are conscious.”
They should immediately stop misleading people through company documentation that models are “blackmailing” people or, as Anthropic did in its Mythos system card, suggest a model has “broken containment and sent a message” when it A) was instructed to do so and B) did not actually break out of any container.
They must stop discussing threats to jobs without actual meaningful data that is significantly more sound than “jobs that might be affected someday but for now we’ve got a chatbot.” Mr. Amodei should immediately cease any and all discussions of AI potentially or otherwise eliminating 50% of white collar jobs, as Mr. Altman should cease predicting when Superintelligence might arrive, as Mr. Amodei should actively reject and denounce any suggestions of AI “creating a white collar bloodbath.”
Those that defend AI labs will claim that these are “difficult conversations that need to be had,” when in actuality they engage in dangerous and frightening rhetoric as a means of boosting a company’s valuation and garnering attention. If either of these men truly believed these things were true, they would do something about it other than saying “you should be scared of us and the things we’re making, and I’m the only one brave enough to say anything.”
These conversations are also nonsensical and misleading when you compare them to what Large Language Models can do, and this rhetoric is a blatant attempt to scare people into paying for software today based on what it absolutely cannot and will not do in the future. It is an attempt to obfuscate the actual efficacy of a technology as a means of deceiving investors, the media and the general public.
Both Altman and Amodei engage in the language of AI doomerism as a means of generating attention, revenue and investment capital, actively selling their software and future investment potential based on their ownership of a technology that they say (disingenuously) is potentially going to take everybody’s jobs.
Based on reports from his Instagram, the man who threw the molotov cocktail at Sam Altman’s house was at least partially inspired by If Anyone Builds It, Everyone Dies, a doomer porn fantasy written by a pair of overly-verbose dunces spreading fearful language about the power of AI, inspired by the fearmongering of Altman himself. Altman suggested in 2023 that one of the authors might deserve the Nobel Peace Prize.
I only see one side engaged in dangerous rhetoric, and it’s the ones that have the most to gain from spreading it.
Cause and Effect
I need to be clear that this act of violence is not something I endorse in any way. I am also glad that nobody was hurt.
I also think we need to be clear about the circumstances — and the rhetoric — that led somebody to do this, and why the AI industry needs to be well aware that the society they’re continually threatening with job loss is one full of people that are very, very close to the edge. This is not about anybody being “deserving” of anything, but a frank evaluation of cause and effect.
People feel like they’re being fucking tortured every time they load social media. Their money doesn’t go as far. Their financial situation has never been worse. Every time they read something it’s a story about ICE patrols or a near-nuclear war in Iran, or that gas is more expensive, or that there’s worrying things happening in private credit. Nobody can afford a house and layoffs are constant.
One group, however, appears to exist in an alternative world where anything they want is possible. They can raise as much money as they want. They can build as big a building as they want anywhere in the world. Everything they do is taken so seriously that the government will call a meeting about it. Every single media outlet talks about everything they do. Your boss forces you to use it. Every piece of software forces you to at least acknowledge that they use it too. Everyone is talking about it with complete certainty despite it not being completely clear why. As many people writhe in continual agony and fear, AI promises — but never quite delivers — some sort of vague utopia at the highest cost known to man.
And these companies are, in no uncertain terms, coming for your job.
That’s what they want to do. They all say it. They use deceptively-worded studies that talk about “AI-exposed” careers to scare and mislead people into believing LLMs are coming for their jobs, all while spreading vague proclamations about how said job loss is imminent but also always 12 months away. Altman even says that jobs that will vanish weren’t real work to begin with, much as former OpenAI CTO Mira Murati said that some creative jobs shouldn’t have existed in the first place.
These people who sell a product with no benefit comparable on any level to its ruinous, trillion-dollar cost are able to get anything they want at a time when those who work hard are given a kick in the fucking teeth, sneered at for not “using AI” that doesn’t actually seem to make their lives easier, and then told that their labor doesn’t constitute “real work.”
At a time when nobody living a normal life feels like they have enough, the AI industry always seems to get more. There’s not enough money for free college or housing or healthcare or daycare but there’s always more money for AI compute.
Regular people face the harshest credit market in generations but private credit and specifically data centers can always get more money and more land.
AI can never fail — it can only be failed. If it doesn’t work, you simply don’t know how to “use AI” properly and will be “at a huge disadvantage" despite the sales pitch being “this is intelligent software that just does stuff.” AI companies can get as much attention as they need, their failings explained away, their meager successes celebrated like the ball dropping on New Years Eve, their half-assed sub-War Of The Worlds “Mythos” horseshit treated like they’ve opened the gates of Hell.
Regular people feel ignored and like they’re not taken seriously, and the people being given the most money and attention are the ones loudly saying “we’re richer than anyone has ever been, we intend to spend more than anyone has ever spent, and we intend to take your job.”
Why are they surprised that somebody mentally unstable took them seriously? Did they not think that people would be angry? Constantly talking about how your company will make an indeterminate amount of people jobless while also being able to raise over $162 billion in the space of two years and taking up as much space on Earth as you please is something that could send somebody over the edge.
Every day the news reminds you that everything sucks and is more expensive unless you’re in AI, where you’ll be given as much money and told you’re the most special person alive. I can imagine it tearing at a person’s soul as the world beats them down. What they did was a disgraceful act of violence.
Unstable people in various stages of torment act in erratic and dangerous ways. The suspect in the molotov cocktail incident apparently had a manifesto where he had listed the names and addresses of both Altman and multiple other AI executives, and, per CNBC, discussed the threat of AI to humanity as a justification for his actions. I am genuinely happy to hear that this person was apprehended without anyone being hurt.
These actions are morally wrong, and are also the direct result of the AI industry’s deceptive and manipulative scare campaign, one promoted by men like Altman and Amodei, as well as doomer fanfiction writers like Yudowsky, and, of course, Daniel Kokotajlo of AI 2027 — both of whom have had their work validated and propagated via the New York Times.
On the subject of “dangerous rhetoric,” I think we need to reckon with the fact that the mainstream media has helped spread harmful propaganda, and that a lack of scrutiny of said propaganda is causing genuine harm.
I also do not hear any attempts by Mr. Altman to deal with the actual, documented threat of AI psychosis, and the people that have been twisted by Large Language Models to take their lives and those of others. These are acts of violence that could have been stopped had ChatGPT and similar applications not been anthropomorphized by design, and trained to be “friendly.”
These dangerous acts of violence were not inspired by Ronan Farrow publishing a piece about Sam Altman. They were caused by a years-long publicity campaign that has, since the beginning, been about how scary the technology is and how much money its owners make.
I separately believe that these executives and their cohort are intentionally scaring people as a means of growing their companies, and that these continual statements of “we’re making something to take your job and we need more money and space to do it” could be construed as a threat by somebody that’s already on edge.
I agree that the dangerous rhetoric around AI must stop. Dario Amodei and Sam Altman must immediately cease their manipulative and disingenuous scare-tactics, and begin describing Large Language Models in terms that match their actual abilities, all while dispensing with any further attempts to extrapolate their future capabilities. Enough with the fluff. Enough with the bullshit. Stop talking about AGI. Start talking about this like regular old software, because that’s all that ChatGPT is.
In the end, if Altman wants to engage with “good-faith criticism,” he should start acting in good faith.
That starts with taking ownership of his role in a global disinformation campaign. It starts with recognizing how the AI industry has sold itself based on spreading mythology with the intent of creating unrest and fear.
And it starts with Altman and his ilk accepting any kind of responsibility for their actions.
I’m not holding my breath.
